

Customer Experience (CX) & Big Data Analytics
oder: Wie mache ich Kunden und mich glücklich? Teil 2
In meinem letzten Artikel zu dem Thema (Wie mache Kunden glücklich Teil 1) hatte ich geschrieben, dass im Zeitalter der allgemeinen Vernetzung und von Business 4.0 für Unternehmen die wichtige Herausforderung entstanden ist, ihre eigenen Kunden über alle Kommunikations- und Servicekanäle hinweg einheitlich anzusprechen und bedienen zu können.
Wenn man jetzt mal schaut, was tatsächlich in dieser Richtung für Aktivitäten existieren, stellt man dann fest, dass viele Unternehmen auch heute noch keine übergreifende Strategie hierzu entwickelt haben. In der Regel findet man Einzellösungen für bestimmte Teilbereiche, jedoch eher selten eine allgemeine Lösung, welche alle Kanäle umfasst und sich leicht betreiben lässt.
Dennoch: Es gibt sie natürlich auch, die positiven Beispiele. Um diese soll es jetzt gehen.
Lambda Architektur
Wie schafft man also die Möglichkeit, die komplexen Wege des Kunden in seiner Beziehung zu mir als Unternehmen nachzuvollziehen? Und das möglichst in Echtzeit? Eine sogenannte Lambda-Architektur! Was ist das genau?
Eine Lambda-Architektur beruht zunächst auf dem Konzept unveränderlicher Daten, was bedeutet, dass
- Veränderungen an Daten nicht über ein Update sondern als Append erfolgt
- Jede Veränderung zu einem neuen Datensatz (Faktum) wird, der zum Veränderungszeitpunkt Gültigkeit hat
- Informationen sich aus den Berechnungen der einzelnen Fakten ergeben. Beispielsweise ist die Anzahl der Klicks in einer Unternehmenswebseite eine Funktion, die die einzelnen Clicks pro Besucher pro Tag zählt. Hier sind die Clicks pro Besucher die Fakten, die Anzahl eine berechnete Information (und Besucher / Zeit Dimensionen)
Man kann sie als eine Architektur zur Massenverarbeitung von Daten beschreiben, die so aufgebaut ist, dass sie Latenz, Durchsatz und Fehlertoleranz in ein vernünftiges Verhältnis bringt. Hierzu werden Echtzeit Streaming Methoden und Batch Methoden gemeinsam eingesetzt und die Daten aus beiden Quellen in einer sinnvollen Art und Weise miteinander verknüpft.
Eine solche Architektur ermöglicht das Zusammenführen von statischen Daten und Echtzeitdaten z.B. zu einer dynamischen Entscheidungsfindung und lässt sich hervorragend als hybrides Datenbank / Big Data System aufsetzen. Sie besteht typischerweise aus folgenden Ebenen:
- Batch Layer für die historischen und statischen Daten
- Speed Layer für die aktuellen und dynamischen Daten
- Service Layer, der die Analytik bzw. Entscheidungen für die Applikationen liefert und somit deren Backend darstellt
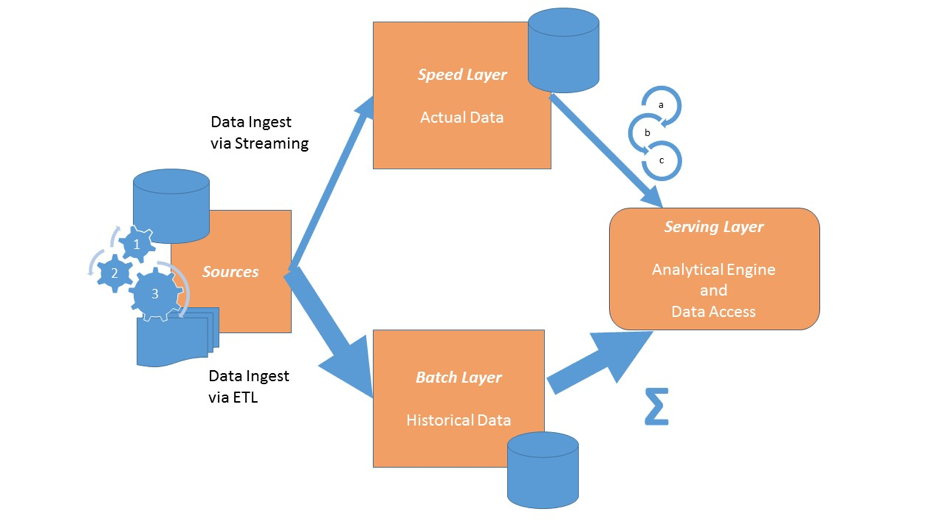
Sources
Als Quellen müssen natürlich alle Kanäle eingebunden werden. Zusätzlich dazu natürlich auch CRM Daten, transaktionale Daten, Log Dateien der Webserver und was auch immer zur Entscheidungsfindung benötigt wird. Wichtig ist eigentlich nur, dass sich diese Daten entweder klassisch per ETL oder mit geeigneten Streaming Lösungen in die verschiedenen Layer einspeisen lassen. Oder aber, dass sie auch direkt einer Real Time Engine zur Verfügung stehen.
Batch Layer
Der Batch Layer enthält die historischen Daten und nach periodischer Aktualisierung auch alle Daten. Sie können redundant gespeichert sein, wie es typischerweise in einer Data Warehouse Umgebung zu finden ist. Hier werden auf den Daten Fakten genannt, die Aggregationen in Batchläufen berechnet. Neue Daten werden zu den vorhandenen Daten hinzugefügt. Es finden keine Updates statt.
Charakteristisch ist mit hoher Latenz aufgrund der großen Datenmenge zu rechnen. Dafür ist das System aber fehlertolerant aufgrund der redundanten Datenspeicherung.
Speed Layer
Der Speed Layer fängt die hohe Latenz des Batch Layers ab, indem er die heißen Daten, d.h. die jeweils neu hinzukommenden Daten, gesondert vorhält, deren Aggregate berechnet, zwischenspeichert und zur Verfügung stellt. Darüber hinaus soll er die Möglichkeit unterstützen, in Echtzeit Analysen durchzuführen, z.B. über eine Real Time Decisioning Engine, deren Ergebnisse der Servicing Layer dann anbietet.
Servicing Layer
Genauso wie der Speed Layer fängt der Servicing Layer die hohe Latenz des Batch Layers ab. Er speichert hierzu redundant Aggregate wie das in einer klassischen Data Warehouse Architektur etwa in separaten Data Marts geschehen würde. Er stellt die gewünschten Informationen weiteren Systemen bereit. Diese können dann die Funktionalitäten und Ergebnisse aus dem Servicing Layer und dem Speed Layer benutzen, um daraus dann Antworten oder gesteuerte Aktionen an die Kunden zurückzugeben.
Implementierungvarianten
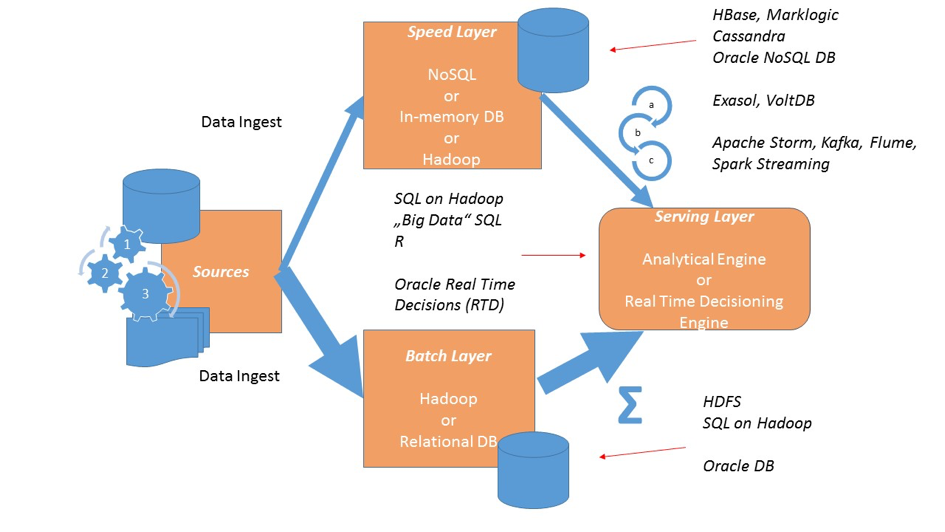
Für den Batch Layer bietet sich außer einem Data Warehouse mit klassischem ETL in einer relationalen Datenbank auch Hadoop an. In diesem Fall wäre das Prozedere wie folgt:
- Neue Daten kommen über ETL als Datenablage ins HDFS
- Berechnungen werden batchorientiert in Hadoop per MapReduce oder in-memory mithilfe der Spark Technologie ausgeführt
- Zugegriffen wird über den Hive Meta Store, der den perfomanten Zugriff mit Impala, Presto, Spark SQL oder aber herstellerspezifischen SQL on Hadoop Lösungen wie bspw. Oracle Big Data SQL ermöglicht
Den Speed-Layer kann mit einem der vielen Streaming Lösungen wie bspw. Apache Storm oder Flume beladen werden. Hierbei bietet sich wieder HDFS und SQL on Hadoop als Technologie an.
Sehr effizient können die heißen Daten aber auch in NoSQL Datenbanken oder in-memory Datenbanksystemen gespeichert werden. Vorteil ist hier der sehr schnelle Datenzugriff, die Skalierbarkeit und die Sicherheit, die gemanagte Datenbanksysteme out-of-the-box anbieten
Je nachdem, welche der vielen Varianten zur Implementierung man konkret wählt
- Nur Hadoop
- Hadoop mit relationaler DB
- Hadoop mit NoSQL DB oder In-Memory DB
- Hadoop mit relationaler DB und NoSQL DB oder In-Memory DB
kann man dann den Servicing Layer konzipieren. Hier bietet sich auf jeden Fall wieder der Zugriff mit SQL auf den Batch und den Speed Layer an. Sowohl Hadoop, als auch NoSQL DBs – was ja nicht NO SQL sondern Not only SQL bedeutet – lassen sich bei Bedarf über SQL einbinden und damit einfach joinen. Analytische Engines oder aber Real-time Engines benötigen in der Regel den sehr schnellen Zugriff auf beide Layer und bieten auch SQL Interfaces hierfür an.
Komplexität
Was also hindert Unternehmen (noch), vermehrt solche Systeme aufzusetzen? Die Komplexität!
Ein solches System, welches aus vielen verschiedenen Komponenten besteht die alle orchestriert werden müssen, ist natürlich eine nichttriviale Geschichte. Und es gilt auch hier natürlich der Ansatz je einfacher man die Architektur gestalten kann umso besser. Der kritischste Teil ist der Speed Layer. Dieser muss richtig getaktet sein und auch in Echtzeit Daten liefern. Kein einfaches Unterfangen.
Schon fertige Lösungen wie Oracle Real Time Decisions nehmen hierbei einen Großteil der Komplexität heraus. Sie können sich direkt in das Streaming der Quellen einklinken und damit quasi als Speed und Servicing Layer in einem agieren, wenn dies gewünscht ist. Die Vorteile einer solchen Lösung liegen auf der Hand.
Resümee
Den Kunden wirklich zu verstehen und so zu bedienen, dass er sich nicht falsch behandelt oder bevormundet fühlt ist eine schwierig zu bewerkstelligende, aber lösbare Aufgabe.
Die hier skizzierte Architektur dient als Blaupause, die konkrete Realisierung kann natürlich auch abweichen. Soweit, so gut.
In einem folgenden Artikel werde ich noch einen Schritt tiefer gehen und die Mechanismen beleuchten, die in Echtzeit kanalübergreifend die richtigen Entscheidungen liefern und dann endlich auch konkrete Systeme die im produktiven Einsatz sind, beschreiben.
Anregungen und Fragen sind wie immer willkommen!



